Turning Content into Data with Intelligent Data Extraction
Extracting your data shouldn’t be like pulling teeth
 As many businesses move to the “nearly” paperless office, they have moved beyond scanning existing paper for storage or archival. Today, businesses demand that the information in their documents is seamlessly available to users. This has led capture software providers to incorporate new and improved technologies so their software “sees” the image, “extracts” the key information and incorporates it into key Enterprise Content Management (ECM), Electronic Medical Records (EMR), Electronic Resource Planning (ERP) or line of business software where it can be shared and used.
As many businesses move to the “nearly” paperless office, they have moved beyond scanning existing paper for storage or archival. Today, businesses demand that the information in their documents is seamlessly available to users. This has led capture software providers to incorporate new and improved technologies so their software “sees” the image, “extracts” the key information and incorporates it into key Enterprise Content Management (ECM), Electronic Medical Records (EMR), Electronic Resource Planning (ERP) or line of business software where it can be shared and used.
Key Elements of Intelligent Data Capture
Three areas are identified as the essence of intelligent data capture.

In the first step, Recognize , capture software must employ technology to turn scanned images into computer-readable text. Next, the software must Extract information by identifying what the important or key information is from the text. And finally, capture software must be able to share or Integrate the key data into ECM, DM, or ERP type systems where the user can consume and use the information.
Recognition: Turning 1’s and O’s Into Text
OCR (Optical Character Recognition)

 OCR is a mature data conversion technology that digitizes text images so that they can be electronically edited, searched, and stored. With OCR you can make your image-based file fully text-searchable or extract select data from it. Full page OCR is used when all content of a document needs to be converted to readable text. With zonal OCR, specific document areas are identified for automatic OCR capture. Additionally, drag-and-drop or rubber band OCR allows an operator to highlight document text which is automatically converted and dropped into index fields.
OCR is a mature data conversion technology that digitizes text images so that they can be electronically edited, searched, and stored. With OCR you can make your image-based file fully text-searchable or extract select data from it. Full page OCR is used when all content of a document needs to be converted to readable text. With zonal OCR, specific document areas are identified for automatic OCR capture. Additionally, drag-and-drop or rubber band OCR allows an operator to highlight document text which is automatically converted and dropped into index fields.
OCR has the greatest impact on the growth of intelligent data extraction and the potential continues to grow as the technologies continue to improve.
Barcode Technology in Data Capture
 Built on proven standards and a successful history, barcode recognition (BCR) offers the most trustworthy recognition technology for data capture. Barcodes identify merchandise and equipment, tag documents and even tag patients in hospital care, all with accuracy that is unmatched by any other classification approach. Barcodes can be used in both structured and unstructured document formats and are far more accurate than OCR.
Built on proven standards and a successful history, barcode recognition (BCR) offers the most trustworthy recognition technology for data capture. Barcodes identify merchandise and equipment, tag documents and even tag patients in hospital care, all with accuracy that is unmatched by any other classification approach. Barcodes can be used in both structured and unstructured document formats and are far more accurate than OCR.
Other Recognition Technologies for Data Capture
ICR (Intelligent Character Recognition)
ICR is a handwriting recognition system that allows fonts and different styles of handwriting to be learned by a computer during processing to improve accuracy and recognition levels. Obviously this technology is not as accurate as OCR, but it does have a limited role in some capture systems and continues to improve in accuracy.
OMR (Optical Mark Recognition)
OMR is the process of capturing human-marked data from document forms such as surveys and tests. Like ICR, lower accuracy limits the application within data capture environments today. Again, the accuracy of this recognition is seeing improvements.
Extract: Locating the Key Information
 After the content has been captured, pattern matching technology identifies the key data or information in the document.
After the content has been captured, pattern matching technology identifies the key data or information in the document.
Regular expressions (regex) provide a fast and powerful method to search, extract and replace specific data found within scanned documents. Regular expressions are essentially a special text string for describing a search pattern. You could think of regular expressions as extremely powerful wildcards.
 Regex’s powerful expressions are extremely flexible and patterns can be constructed to match almost anything. For text commonly found in documents such as dates, SSNs, ZIP codes etc., patterns are freely available on the Internet. Here are some examples:
Regex’s powerful expressions are extremely flexible and patterns can be constructed to match almost anything. For text commonly found in documents such as dates, SSNs, ZIP codes etc., patterns are freely available on the Internet. Here are some examples:
|
ZIP Codes - ^(?!00000)(? |
|
US Phone Number - ^([0-9]( |-)?)?(\(?[0-9]{3}\)?|[0-9]{3})( |-)?([0-9]{3}( |-)?[0-9]{4}|[a-zA-Z0-9]{7})$ |
|
Credit Card - (^(4|5)\d{3}-?\d{4}-?\d{4}-?\d{4}|(4|5)\d{15})|(^(6011)-?\d{4}-?\d{4}-?\d{4}|(6011)-?\d{12})|(^((3\d{3}))-\d{6}-\d{5}|^((3\d{14}))) |
Lookahead and Lookbehind
The Lookahead and Lookbehind features go beyond basic zonal OCR and let you identify and extract data from unstructured documents with data found anywhere on the scan. This entails searching for an identifiable keyword or string, like “PO Number” or related derivatives (Purchase Order Number), and then a word pattern to identify the desired text to capture before or after the specified matching word.
Line Item Extraction
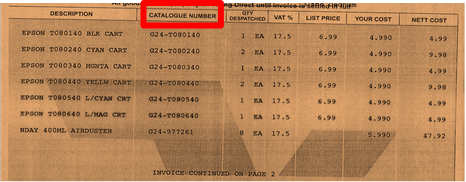
One of the more complex challenges is the need to capture column-based data, or data where the text is not adjacent to a matching word. Often called Line Item Extraction, this technique is used in applications where the desired text to capture is often found below the keyword. For a real world example, here is a partial invoice where you might need to capture the "Catalogue Number“ using Line Item Extraction techniques.
What Can the Capture Software Do with Identified Data?
So once the key data has been identified or “extracted”, how can the capture software add “intelligence”?
- Split Files
A large single file can be split into multiple files based on information extracted from barcodes and content. - Name Files and Folders
Name files, folders and subfolders with extracted information from the file or system information. - Route Files
Route the files to another directory (and even create the folder and subfolder names) using content. - Index
Create indexes from extracted information for the “searchable” fields. - Create PDF Bookmarks
Create PDF bookmarks based on extracted information. - Validate
Data can be validated against business rules to reduce errors.
Integrate: Share, Making Data Available to Users
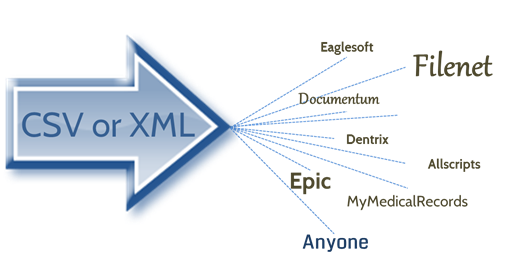
Integration means sharing the information with the user. The key data can be sent to the user's system via standard XML to CSV file. These data transfer standard formats are accepted by virtually any database. The end users' system could be a simple search and retrieval system, a document management system or ECM system or a more specific system such as an ERP system.
What Does the Future Hold for Intelligent Data Capture?
Users will continue to demand increasingly smarter interpretation of their content and push to access real data seamlessly. The technology will see improvements in speed, accuracy and scope. And, as with most information technology trends today, increased mobile and cloud computing will be seen in intelligent data capture. In this environment, information governance and compliance will be tested and companies will need increased technical support to manage the increasing complexity. In summary, the following will characterize the intelligent data capture direction.
- Continued Improvement in Recognition Technologies Including:
OCR expansion to include services like translation
Better accuracy of ICR and OMR
Faster, more accurate results - Increased Mobility Integration For Smart Phones, Tablets, etc
- Increased Cloud Computing Based Services
- Improved Validation Against Complex Business Rules
- Increased Technical Support to Manage the Complexity
- Increased Information Governance and Compliance Issues and Complexity
Learn More
There is no better time to get started than now. Find out about ImageRamp, our capture platform, and send us an email to discuss your capture challenges.