Ignoring Barcodes for Split and Naming
Common practices to optimize scanning and data extraction for your scanned or PDF documents.
|
Documents can often contain a number of barcodes, but they may not be the specific barcodes you are looking for.
|
asd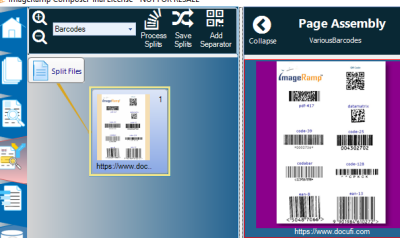 f f |
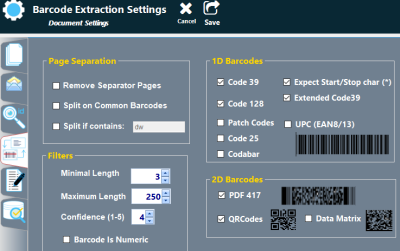
Setting up your Barcode Ignoring ConditionsIgnoring barcodes by value length: One simple approach is to use the Minimal Barcode Length option with ImageRamp. This setting allows you to identify that you only want the system to capture barcodes that are greater or equal to the minimal length identified. In the example below, we are only extracting barcodes that are 14 characters or greater in length.
Ignore Barcode Split pages that contain a value: Another common example is companies have text designations on barcodes that are intended to act as the split identifier designating a new document. In our example we are indicating that splits are to be made when ImageRamp encounters pages with the string “ID:” contained in the resulting text. All other split conditions are ignored.
Ignore Barcodes based on type: There are a number of barcode types and each can be enabled or disabled to help select the specific values desired. This includes both 2D and 1D types. |
 |
Loading and Testing your Barcode File
As an example, in the document below, we have social documents containing two distnict ID’s, however the older form is less than the number of characters used in the desired and second barcode value. Using the Minimal length, we are able to have ImageRamp ignore the undesired ID and use the proper ID located at the base of the document.